2月8日,海外开发者社区OpenRouter上出现了一个代号为“Pony Alpha”的匿名模型。开发者们震惊地发现这个神秘模型在完全无人干预下,竟能自主修复代码、读取日志,耗时数天构建出一个可用的C语言编译器;甚至有人用它从零开发了手机应用国内正规最大的配资平台,直接打包上架了应用商店。硅谷开发者们纷纷猜测这到底是GPT的最新模型,还是Claude的秘密测试,又或是DeepSeek的新成果。
2月11日深夜,谜底揭晓。中国AI公司智谱发布开源旗舰模型GLM-5。Pony Alpha的身份随之揭晓——被硅谷追捧的神秘模型来自中国。关于“智谱新模型全球登顶”的话题迅速霸占榜首,引发了一场属于智谱的“现象级共振”。

在产品端,GLM Coding Plan上线即售罄,官方不得不启动限售和紧急扩容。在资本端,华尔街投行摩根大通首次将智谱纳入研究覆盖,给予“买入”评级,定位为“捕捉下一波全球AI浪潮的首选标的”。市场随即用真金白银投出赞成票:GLM-5官宣后,智谱股价单日一度大涨40%,周涨幅高达120%。

在政策端,总书记考察时智谱创始人唐杰作为大模型企业负责人进行汇报,同一周国务院也举行专题学习,明确强调“深化拓展‘人工智能+’全方位赋能千行百业”。技术突破、资本重估、顶层设计,三股力量在2026年的春节完成了历史性的交汇。
如果说2025年的春节是DeepSeek的“孤勇者时刻”,那2026年的春节,中国AI呈现出的是另一种面貌——不再是单一企业的单点突破,而是一场视觉、工程、基座三线齐发的集团突破。中国AI界实质上已经完成了数字时代的“两弹一星”战略部署。

这场属于中国AI的“集体崛起”,源于核心生产力的实打实跃升。相比美国AI界更多的技术导向,中国AI则一直和产业发展紧密绑定。视觉生成与Agentic Coding(智能体编程)是当下AI领域公认的两条天花板最高、且能够直接服务万亿量级实体经济的核心航道。
AI视频不仅重塑人类的感官体验,也将重新定义内容制作流程和影响消费市场;而智能体编程则将重塑软件产业的生产方式——从“AI辅助写代码”进化到“AI独立完成系统工程”。在这两条赛道上,中国AI都已经实现了新的突破。
视觉航道上,Seedance 2.0给出的答卷已经不需要太多论证——全网的刷屏就是最好的背书。这款被字节跳动定位为“可导演的电影级全流程生成引擎”的模型,采用双分支扩散变换器架构,可以同步生成视频与音频。只需要输入提示词或上传一张参考图,它就能产出带完整原生音轨的多镜头视频。

在海外社交平台,AI影视创作领域最活跃的创作者之一el.cine坦言:“学了7年数字电影制作,现在感觉90%都白学了。”他用Seedance 2.0制作的第一条短片就引爆了关注——画面中一名男子在人群中狂奔、撞翻水果摊、被警察追逐,运镜、光影、表情、镜头语言近乎无可挑剔。网友的反应很直接:“我甚至不确定这是真的还是假的。”
而在国内,游戏科学CEO冯骥给出了“当前地表最强的视频生成模型”的评价。他在微博上写道:“AI理解多模态信息并整合的能力完成了一次飞跃,令人惊叹。”
GLM-5要回答的是另一个更硬核的问题:中国AI能不能造系统?真实的软件工程需要持续数天的架构设计,需要在几万行代码之间维护逻辑一致性,需要在编译报错时自己去读日志、定位问题、改了再试,反复迭代直到系统跑通。简单说,它需要的不是一个能接话的“副驾驶”,而是一个能独立扛活的工程师。
实际上,硅谷已经在押注这个方向。Anthropic的Claude Opus 4.6和OpenAI的GPT-5.3 Codex都在最新版本中重点强调同一个词——“Agentic”,也就是让AI以智能体的方式长时间自主运行,处理过去需要资深工程师花好几天才能搞定的系统级任务。
Pony Alpha在社区引起关注,正是因为它展示的是这种能力。C编译器案例之所以被反复引用,元鼎证券配资平台是因为这类任务要求模型在数天跨度内、几百次工具调用和上下文接力中维持逻辑连贯——中间任何一步出错,后面整条链都会崩塌。跑通了,说明模型在长程规划上的鲁棒性过了一个关键门槛。
开发者们用 GLM-5 制作出了横版解谜游戏、Agent 交互世界、论文版“抖音”等应用,这些应用已开放下载,或已提交商店审核。这些案例验证了一个从产品构思、前后端架构、数据抓取逻辑到最终打包上架App Store的完整闭环,全程由模型主导完成。
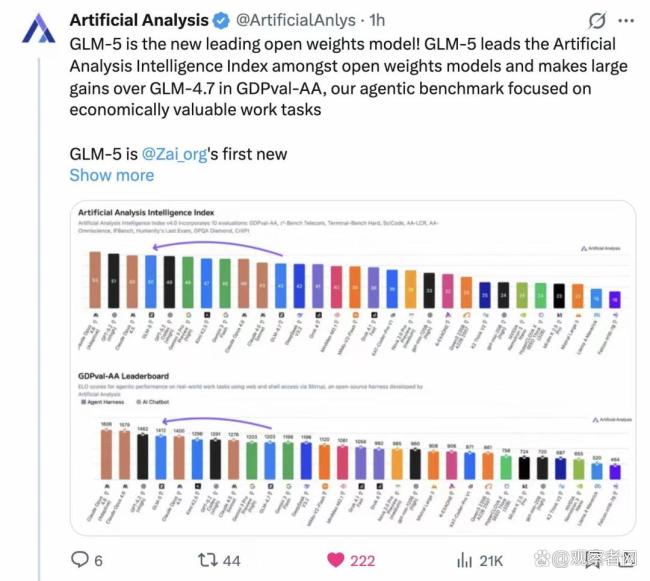
第三方AI评测机构Artificial Analysis在GLM-5发布后更新了榜单。GLM-5已成为开源模型中的新领导者,在综合智能指数和Agentic能力两个维度均位列开源第一。在编程领域的核心评测SWE-bench Verified上,GLM-5拿到了77.4分,超过了Google的Gemini 3.0 Pro。
如果只看到Seedance和GLM-5两个产品,就低估了这个春节真正的含金量。在两个显性事件之下,一整套支撑它们的生态正在完成系统性的咬合。DeepSeek悄然推送了版本更新,上下文处理能力从128K Token大幅跃升至100万Token——这意味着它可以一次性处理《三体》三部曲体量的完整文本。社区已经普遍将这次更新解读为DeepSeek V4的灰度测试前兆。
GLM-5在架构层面首次集成了DeepSeek的Sparse Attention机制。作为DeepSeek在长文本处理上的一项核心创新,能在维持模型效果的同时大幅降低计算成本。GLM-5将其吸收进了自己的架构,并在此基础上跑出了逼近Claude Opus 4.5的成绩。这意味着DeepSeek的核心技术创新已经开始以“外溢”的方式被中国AI生态中的其他企业吸收和采用。
当一个开源模型在长程任务规划和自主纠错上开始逼近闭源头部水平,这条分工链的逻辑基础就开始松动了。规划和执行可以由同一个开源模型一站式完成,开发者不再需要为“大脑”单独向昂贵的闭源API付费。
行业变革往往不发生在“超越”的那一刻,而发生在“够用”的那一刻。当开源的能力上限摸到了闭源的门槛,闭源一方的定价权就会开始承受压力。正是因为察觉到了这种底层商业逻辑的松动,华尔街的视线开始向东方转移。全球顶级投行对中国大模型公司给出的史无前例的高估值与核心站位,本质上是在用真金白银发出信号:资本市场正在重新评估中国AI基座企业的价值锚点。
而在算力层,GLM-5的推理集群已大量运行在国产芯片之上——华为昇腾、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光,模型完成了与这些国产算力平台的深度适配。面对产品上线后瞬间涌入的数以百万计的真实流量冲击,接住这波算力挤兑并完成紧急扩容的,正是这些国产芯片集群。
这也意味着从模型权重到推理算力,GLM-5跑通了一条不依赖英伟达的技术全链路。一年前,中国AI的叙事集中在“谁是下一个DeepSeek”——一种单一英雄式的期待。而仅仅一年之后,这个生态已经从一枝独秀进化为一套完整的、自主可控的技术体系,企业之间不再是零和博弈,而是在不同层面上互相支撑、系统性地抬高整体水位。
至此,中国AI界在2026年春节的这场技术爆发,已经实质性地完成了数字时代的“两弹一星”战略部署。Seedance 2.0是炸开感官天花板的“视觉之弹”。GLM-5是砸穿生产力深水区的“工程之弹”。DeepSeek则是那颗高悬于顶的“生态卫星”。它的核心技术正以外溢的方式为整个中国AI生态提供底层导航,让企业之间形成了强大的技术互通。
中国AI从一枝独秀,进化为在最核心赛道上同时出牌、且拥有全生态战略底座的成建制军团。而且这支军团的牌还没有出完。DeepSeek的旗舰级更新可能才刚刚露出冰山一角,字节跳动旗下的通用大模型豆包2.0已在内测中蓄势待发,阿里旗下的千问3.5同样被外界视为即将亮相的重磅选手。
当这些牌在未来几周内陆续打出,这个春节开启的中国AI故事还远未写完。半年后的今天,这场发生在春节的技术交卷证明了Altman的焦虑正在变成现实。中国AI展示出来的,已经不再是单点的技术突围,而是一种成体系的底层输出。视觉生成、系统工程、开源生态、基座模型、国产算力——五条战线在同一个时间窗口里各自交出了世界级的答卷,并且在技术底层实现了深度咬合。
当摩根大通开始用“首选标的”来定位中国大模型公司,当硅谷技术圈为“Pony Alpha”彻夜沸腾,华尔街与硅谷显然都在被迫修正他们对中国科技实力的评估框架。如果2025年春节是DeepSeek的单刀赴会,那2026年春节国内正规最大的配资平台,AI战场上站着的已经是一支重塑全球版图的中国集团军。中国AI正在从追赶者变成基础设施的定义者——这个进程已经不可逆转。
元鼎证券配资平台提示:本文来自互联网,不代表本网站观点。




